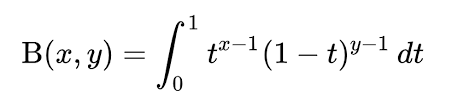

The Beta Function
In Bayesian statistics, often the Beta function is used as the prior distribution for some unknown parameter in a Bernoulli experiment. In this post we compute some properties of the Beta function.
The PDF
The PDF of the Beta function with $\alpha > 0$ and $\beta >0$ looks like
\[f_X(x) = \begin{cases} \frac{1}{B(\alpha, \beta)}x^{\alpha-1}(1-x)^{\beta-1},& \text{if } 0\leq x \leq 1\\ 0, & \text{otherwise} \end{cases}\]Here the normalizing constant is
\[B(\alpha, \beta) = \int^1_0 x^{\alpha-1}(1-x)^{\beta-1}\,dx\]The normalizing constant
It turns out that the normalizing constant can also be written as
\[B(\alpha, \beta) = \frac{(\alpha-1)!(\beta-1)!}{(\alpha+\beta-1)!}\]Relationship to the Binomial coefficient
This allows us to relate it to the Binomial coefficient. Recall
\[\begin{aligned} \binom{n}{k}&=\frac{n!}{k!(n-k)!}\\ &=\frac{1}{n+1}\frac{(n+1)!}{k!(n-k)!} \end{aligned}\]and since
\[B(k+1, n-k+1) = \frac{k!(n-k)!}{(n+1)!}\]we conclude that
\[\binom{n}{k}=\frac{1}{n+1}\frac{1}{B(k+1, n-k+1)}\]Proof of the factorial form of the normalizing constant
Instead of doing hardcode integrals, there is a nice probabilistic proof of this form.
Assume we have $\alpha+\beta+1$ random variables, $Y, Y_1, \dots, Y_{\alpha+\beta}$, which are independent and uniformly distributed over the interval $[0,1]$. Let $A$ be the event
\[A={Y_1 \leq \dots \leq Y_{\alpha}\leq Y \leq Y_{\alpha+1}\leq\dots\leq Y_{\alpha+\beta}}\]The probability of this event is
\[P(A)=\frac{1}{(\alpha+\beta+1)!}\]because there are $(\alpha+\beta+1)!$ ways of ordering and each is as likely as any other.
Next consider the 2 events:
\[B=\{\text{max}\{Y_1,\dots,Y_{\alpha}\}\leq Y\},\]and
\[C=\{Y\leq\text{min}\{Y_{\alpha+1},\dots,Y_{\alpha+\beta+1}\}\},\]Now using the total probability theorem we have
\[\begin{aligned} P(B \cap C) &= \int^1_0 P(B \cap C|Y=y)f_Y(y)dy\\ &=\int^1_0 P(\text{max}\{Y_1,\dots,Y_{\alpha}\} \leq y \leq \text{min}\{Y_{\alpha+1},\dots,Y_{\alpha+\beta}\})\\ &=\int^1_0 P(\text{max}\{Y_1,\dots,Y_{\alpha}\} \leq y)P(y \leq \text{min}\{Y_{\alpha+1},\dots,Y_{\alpha+\beta}\})\\ &=\int^1_0 \prod_{i=1}^{\alpha}P(Y_i \leq y)\prod_{j={\alpha+1}}^{\alpha+\beta}P(Y_j \leq y)\\ &=\int^1_0 y^{\alpha}(1-y)^{\beta}dy \end{aligned}\]where the third and second to last lines followed by independence and the last line by the fact the random variables are uniformly distributed on $[0,1]$ so $P(Y_i \leq y) = y$
We also know that
\[P(A|B \cap C) = \frac{1}{\alpha!\beta!}\]because given $B$ and $C$ there are $\alpha!$ orderings of $Y_1,\dots, Y_{\alpha}$ and $\beta!$ orderings of $Y_{\alpha+1}, \dots, Y_{\alpha+\beta}$ all of which are equally likely.
We know that
\[P(A) = P(B \cap C)P(A|B \cap C)\]so plugging in the above quantities leads us to
\[\frac{1}{(\alpha+\beta+1)!}=\frac{1}{\alpha!\beta!}\int^1_0 y^{\alpha}(1-y)^{\beta}dy\]from which easily follows that
\[\int^1_0 y^{\alpha}(1-y)^{\beta}dy = \frac{\alpha!\beta!}{(\alpha+\beta+1)!}\]This can be written as
\[B(\alpha+1, \beta+1) = \frac{\alpha!\beta!}{(\alpha+\beta+1)!}\]or
\[B(\alpha, \beta) = \frac{(\alpha-1)!(\beta-1)!}{(\alpha+\beta-1)!}\]Expectation
The mth moment of a random variable distributed according to a Beta distribution is given by
\[\begin{aligned} \mathbb{E}\left[X^m\right]&=\frac{1}{B(\alpha, \beta)}\int^1_0 x^m x^{\alpha-1}(1-x)^{\beta-1}dx\\ &=\frac{B(\alpha+m, \beta)}{B(\alpha, \beta)}\\ &=\frac{(\alpha+\beta-1)!}{(\alpha-1)!(\beta-1)!}\times \frac{(\alpha+m-1)!(\beta-1)!}{(\alpha+m+\beta-1)!}\\ &=\frac{(\alpha+\beta-1)!}{(\alpha-1)!}\times \frac{(\alpha+m-1)!}{(\alpha+m+\beta-1)!}\\ &=\frac{(\alpha+\beta-1)!}{(\alpha+m+\beta-1)!}\times \frac{(\alpha+m-1)!}{(\alpha-1)!}\\ &=\frac{(\alpha+m-1)!\dots(\alpha+1)\alpha}{(\alpha+m+\beta-1)\dots(\alpha+\beta+1)(\alpha+\beta)} \end{aligned}\]Bernoulli experiment with a Beta prior
In the Bayesian framework, let’s say we have some prior belief about the edge of a coin. Maybe we think it’s most likely to be somewhere around $1/2$ and less likely to be $0$ or $1$. We treat the parameter $p$ as if it were a random variable, and in a Bernoulli experiment like this, a Beta distribution would be a common prior to choose:
\[p \sim \text{Beta}(a, a)\]and
\[\pi(p) \propto p^{a-1}(1-p)^{a-1}\, p\in (0,1)\]We don’t care about the normalization constant, since it does not depend on $p$, and later when we obtain the posterior distribution, we will just calculate the normalization constant by ensuring the probability sums to one anyway.
Now given some $p$, our observations are random variables that follow $X_1, \dots, X_n \stackrel{iid}{\sim} \text{Ber}(p)$, so that the likelihood is
\[L_n(X_1, \dots, X_n|p)=p^{\sum^n_{i=1}\mathbb{X_i}}(1-p)^{n-\sum^n_{i=1}\mathbb{X_i}}\]where here $\mathbb{X_i} = \mathbb{1}(X_i=1)$, i.e. the indicator that is $1$ when we observe heads and $0$ when we observe tails. If we were doing frequentist statistics we would now do something like take the log-likelihood and differentiate to get the maximum-likelihood estimator (MLE), which in this case would tell us $p^{\text{MLE}}=\bar{X_n}$.
But in Bayesian statistics, we want to get the distribution of the parameter given the data (the posterior) from the distribution of the data given the parameter (the likelihood) and the prior distribution.
Bayes’ law tells us that up to a normalization constant that does not depend on the parameter, we obtain the posterior distribution by just multiplying together the prior and the likelihood:
\[\begin{aligned} \pi(p|X_1, \dots, X_n) &\propto L_n(X_1, \dots, X_n|p)\times \pi(p) \\ &=p^{\sum^n_{i=1}\mathbb{X_i}}(1-p)^{n-\sum^n_{i=1}\mathbb{X_i}}p^{a-1}(1-p)^{a-1}\\ &=p^{a+\sum^n_{i=1}\mathbb{X_i}-1}(1-p)^{a+n-\sum^n_{i=1}\mathbb{X_i}-1}\\ &=\text{Beta}(a+\sum^n_{i=1}\mathbb{X_i}, a+n-\sum^n_{i=1}\mathbb{X_i}) \end{aligned}\]Note that we started with a Beta-prior and we got a Beta-posterior. These are known as conjugate distributions.

Comments