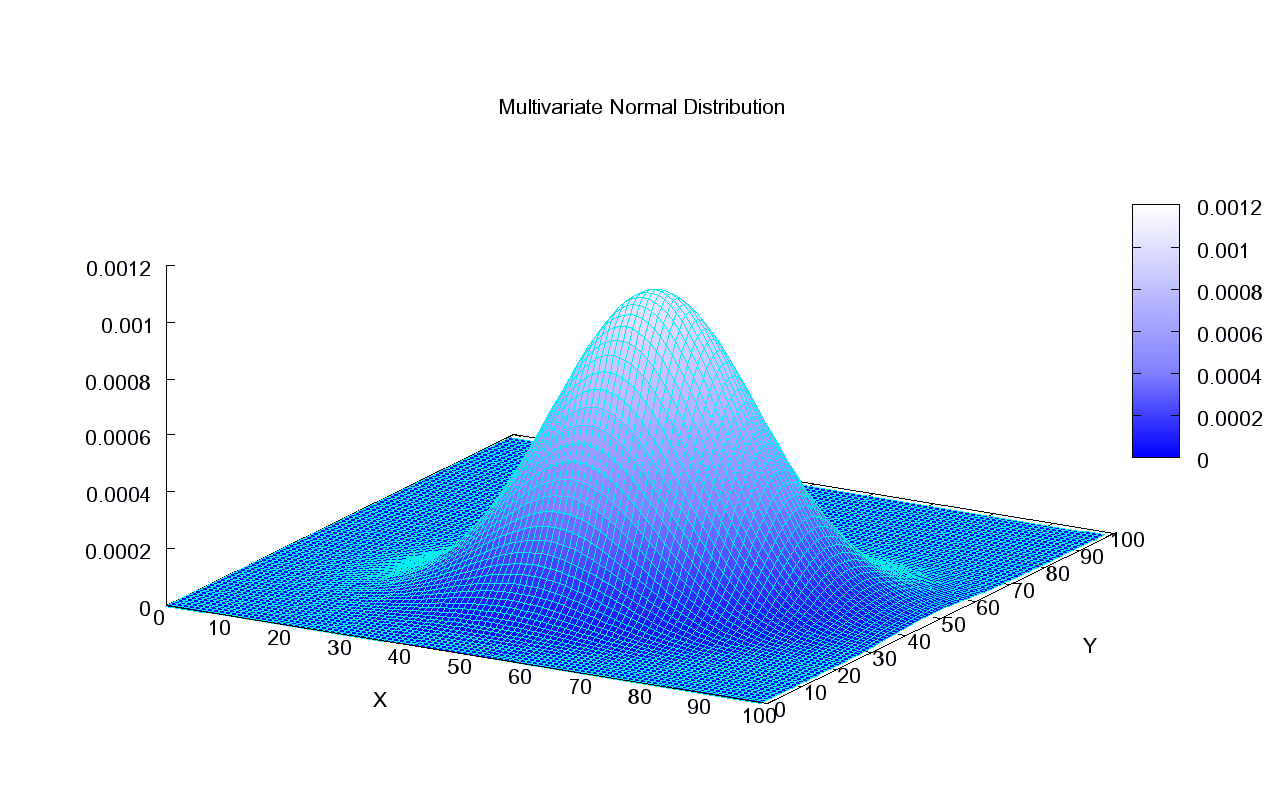

Multidimensional Central Limit Theorem
Instead of just having a single random variable $X$, we may have an experiment for which we are recording several random variables, which we can consider as a random vector in
\[\mathbf{X} = (X^{(1)}, \dots, X^{(d)})^T\]Here we have a $d$ dimensional vector.
Note that in the univariate case we had $X_1, X_2, \dots, X_n$, were the subscripts denoted the trial/sample in a repeat of the experiment (e.g. $i$th roll of a dice and a single number recording the result). In the multivariate case, we would get a vector of results on every single trial, e.g.
\[\begin{aligned} \mathbf{X}_0 &= (X^{(1)}_0, \dots, X^{(d)}_0)^T\\ \vdots\\ \mathbf{X}_n &= (X^{(1)}_n, \dots, X^{(d)}_n)^T\\ \end{aligned}\]Gaussian Random Variables
Such a random vector is a Gaussian vector if any linear combination of its components is a univariate Gaussian variable.
In other words if $\alpha^T \mathbf{X}$ is a univariate Gaussian for any non-zero vector $\alpha \in \mathbb{R}^d$
This is much stronger than just demanding that the components individually are univariate Gaussians; we are demanding that any linear combination of them is Gaussian. Projecting the vector onto any $d$-dimensional vector $\alpha$ we still want a Gaussian.
The distribution of $\mathbf{X}$m the $d$-dimensional Gaussian distribution is completely specified by the mean $\mathbf{\mu} = \mathbb{E}[\mathbf{X}]$ (note that this is a vector whose components are the means of the components $(\mathbb{E}[X^{(1)}], \dots, \mathbb{E}[X^{(d)}])^T$) and also the $d\times d$ covariance matrix $\Sigma$, which captures how the components interact with one another. If $\Sigma$ is invertible, then the PDF of $\mathbf{X}$ is
\[f_{\mathbf{X}}(\mathbf{x})=\frac{1}{\sqrt{(2\pi)^d\text{det}(\Sigma)}}\text{exp}\left[-\frac{1}{2}(\mathbf{x}-\mathbf{\mu})^T\Sigma^{-1}(\mathbf{x}-\mathbf{\mu})\right]\]Notice that the argument of the exponent has dimension $(1 \times d) \times (d \times d) \times (d \times 1) = 1 \times 1$, i.e. it is a scalar.
Note that if the components of our random vector are indeed independent, then the covariance matrix $\Sigma$ would be diagonal and the argument of the exponent would reduce to
\[\sum_{i=1}^d \frac{(\mathbf{x}_i-\mathbf{\mu}_i)^2}{2\sigma_i^2}\]and $\text{det}(\Sigma) = \prod_{i=1}^d \sigma_i^2$]
Meaning the PDF reduces to the product of the marginal PDFs, as expected for independent random variables
\[f_{\mathbf{X}}(\mathbf{x})=\frac{1}{\sqrt{(2\pi)^d\sigma_1^2}}\text{exp}\left({-\frac{(\mathbf{x}_1-\mathbf{\mu}_1)^2}{2\sigma_1^2}}\right) \times \dots \times \frac{1}{\sqrt{(2\pi)^d\sigma_d^2}}\text{exp}\left({-\frac{(\mathbf{x}_d-\mathbf{\mu}_d)^2}{2\sigma_d^2}}\right)\]Covariance matrix
The covariance of a random vector $\mathbf{X}=(\mathbf{X}^{(1)}, \dots, \mathbf{X}^{(d)})$ is a measure of how its components vary with one another
\[\Sigma_{ij} = \text{Cov}(\mathbf{X}^{(i)}, \mathbf{X}^{(j)})\]and remember the definition of covariance between 2 univariate random variables (scalar random variables) is
\[\text{Cov}(\mathbf{X}^{(i)}, \mathbf{X}^{(j)}) = \sum_{k=1}^n \left(\mathbf{X}^{(i)}_k-\mathbb{E}[\mathbf{X}^{(i)}_k]\right)\left(\mathbf{X}^{(j)}_k-\mathbb{E}[\mathbf{X}^{(j)}_k]\right)\]This notation is quite dense, but its important to remember that here we are fixing 2 components of the random vector $i$ and $j$ (maybe we are comparing the first component with the second component) and we are looking at how these things vary over our $n$ observations. If $i=j$ then we are looking at the variance of a single component, a scalar random variable over our observations.
The covariance matrix, $\Sigma$, packs a lot of information. It has pair-wise covariances for all combinations of the components of our random vector over all observations!
Affine transformations
This is a fancy word that basically just means simple linear transformations.
Remember in the univariate case we had the rule that $\text{var}(aX+b)=a^2\text{var}(X)$, analogously consider
\[\mathbf{Y} = \mathbf{A}\mathbf{X}+\mathbf{B}\]where now $A$ is a $k \times d$ dimensional matrix of constants, and $B$ is a $k$-dimensional constant vector, meaning we have $\mathbf{Y}$ as a new $k$-dimensional random vector. The covariance matrix of $\mathbf{X}$ will be the $d\times d$ dimensional $\Sigma_{\mathbf{X}}$ and the covariance matrix of $\mathbf{Y}$ will be the $k \times k$ dimensional matrix $\Sigma_{\mathbf{Y}}$. Also we denote the mean (vectors) as $\mathbf{\mu}{\mathbf{X}}$ and $\mathbf{\mu}{\mathbf{Y}}$.
Consider the mean of $\mathbf{Y}$:
\[\mathbf{\mu}_{\mathbf{Y}} = \mathbb{E}[ \mathbf{A}\mathbf{X}+\mathbf{B}]=\mathbb{E}[ \mathbf{A}\mathbf{X}]+\mathbf{B}=\mathbf{A}\mu_{\mathbf{X}}+\mathbf{B}\]and the covariance
\[\begin{aligned} \Sigma_{\mathbf{Y}}&=\mathbb{E}\left[\left(\mathbf{A}\mathbf{X}+\mathbf{B}-\mathbf{\mu}_{\mathbf{Y}}\right)\left(\mathbf{A}\mathbf{X}+\mathbf{B}-\mathbf{\mu}_{\mathbf{Y}}\right)^T\right]\\ &=\mathbb{E}\left[\left(\mathbf{A}\mathbf{X}+\mathbf{B}-\mathbf{A}\mu_{\mathbf{X}}-\mathbf{B}\right)\left(\mathbf{A}\mathbf{X}+\mathbf{B}-\mathbf{A}\mu_{\mathbf{X}}-\mathbf{B}\right)^T\right]\\ &=\mathbb{E}\left[\left(\mathbf{A}\mathbf{X}-\mathbf{A}\mu_{\mathbf{X}}\right)\left(\mathbf{A}\mathbf{X}-\mathbf{A}\mu_{\mathbf{X}}\right)^T\right]\\ &=\mathbb{E}\left[\left(\mathbf{A}\left(\mathbf{X}-\mu_{\mathbf{X}}\right)\right)\left(\mathbf{A}\left(\mathbf{X}-\mu_{\mathbf{X}}\right)\right)^T\right]\\ &=\mathbb{E}\left[\mathbf{A}\left(\mathbf{X}-\mu_{\mathbf{X}}\right)\left(\mathbf{X}-\mu_{\mathbf{X}}\right)^T \mathbf{A}^T\right]\\ &=\mathbf{A}\mathbb{E}\left[\left(\mathbf{X}-\mu_{\mathbf{X}}\right)\left(\mathbf{X}-\mu_{\mathbf{X}}\right)^T \right]\mathbf{A}^T\\ &=\mathbf{A}\Sigma_{\mathbf{X}}\mathbf{A}^T\\ \end{aligned}\]as you can see this is $(k \times d) \times (d \times d) \times (d \times k)=(k \times k)$ dimensional as expected.
It is the analogy for the univariate $\text{var}(aX)=a^2 \text{var}(X)$ rule we had.
Diagonalization of the covariance matrix
We know that the covariance matrix is symmetric, $\Sigma=\Sigma^T$, since covariance itself is a symmetric operation $\text{cov}(X, Y) = \text{cov}(Y, X)$
We could diagonalize $\Sigma$ by transforming into a basis of its eigenvectors.
\[\mathbf{D} = \mathbf{U}\Sigma\mathbf{U}^T\]where here $\mathbf{U}$ is an orthogonal matrix ($\mathbf{U}\mathbf{U}^T=\mathbf{U}^T\mathbf{U}=\mathbf{I}$) which has the eigenvectors of $\Sigma$ for its rows.
This also means we can write
\[\Sigma = \mathbf{U}^T\mathbf{D}\mathbf{U}\]Multivariate CLT
With that background out of the way, let’s consider how the CLT would look in multidimensions.
Remember in the univariate case the CLT looked like
\[\sqrt{n}\frac{(X_n - \mu)}{\sqrt{\sigma^2}} \xrightarrow[n \to \infty]{(d)} \mathcal{N}(0, 1)\]so it probably wouldn’t be a bad guess to expect that the vector version will look like
\[\sqrt{n}\Sigma^{-1/2} (\mathbf{X}_n - \mathbf{\mu})\xrightarrow[n \to \infty]{(d)} \mathcal{N}_d(\mathbf{0}, \mathbf{I}_{d\times d})\]with $\mathcal{N}d (\mathbf{0}, \mathbf{I}{d\times d})$ being the $d$-dimensional standard Normal distribution.
The tricky thing is that convergence in distribution of a random vector is not implied by convergence in each of its components as you might have guessed.
A sequence of random vectors $\mathbf{T}_1, \mathbf{T}_2, \dots, \mathbf{T}_n$ in $\in \mathbb{R}^d$ converges to a random vector $\mathbf{T}$ if
\[\mathbf{v}^T \mathbf{T}_n \xrightarrow[n \to \infty]{(d)} \mathbf{v}^T \mathbf{T}\,\,\,\, , \forall\, \mathbf{v}\in \mathbb{R}^d\]The sequence $(\mathbf{T}n){n\ge 1}$ only converges if its dot product with any constant vector $\mathbf{v}$ converges in distribution.
Univariate CLT implies multivariate CLT
Let $\mathbf{v} \in \mathbb{R}^d$ and $Y_i = \mathbf{v}^T\mathbf{X}_i$ (remember the subscript refrs to a vector observation, not a component in the vector).
This means $Y_i$ will be a scalar random variable. It has mean and variance
\[\mathbb{E}[Y] = \mathbf{v}^T \mathbb{E}[\mathbf{X}]\]and as we showed in the affine transformations section (only now with $\mathbf{A}=\mathbf{v}^T)$, the variance of $Y$ is
\[\Sigma_{Y}=\mathbf{v}^T\Sigma_{\mathbf{X}}\mathbf{v}\]This is $(1\times d)\times (d \times d) \times (d \times 1)$ and is therefore just $1\times 1$ scalar, the variance of the univariate $Y$, or $\sigma_{Y}^2$.
Hence $(Y_n)_{n\ge 1}$ will satisfy the univariate CLT (note we are looking now at the sample mean of $Y$):
\[\sqrt{n}(\bar{Y}_n - \mathbf{v}^T\mathbf{\mu}_{\mathbf{X}}) \xrightarrow[n \to \infty]{(d)} \mathcal{N}(0, \mathbf{v}^T\Sigma_{\mathbf{X}}\mathbf{v})\]However consider what we have on the right-hand side here. If we have a multivariate Gaussian variable $\mathbf{Z}\sim \mathcal{N}d(\mathbf{0}, \Sigma{\mathbf{X}})$, then for any constant vector $\mathbf{v} \in \mathbb{R}^d$ we have that $\mathbf{v}^T \mathbf{Z}$ is a univariate Gaussian (this was the definition of the multivariate Gaussian in fact). As per the discussion in the affine section, $\mathbf{v}^T \mathbf{Z}$ would have variance $\mathbf{v}^T\Sigma_{\mathbf{X}}\mathbf{v}$, so we have that $\mathbf{v}^T \mathbf{Z} \sim \mathcal{N}(0, \mathbf{v}^T\Sigma_{\mathbf{X}}\mathbf{v})$ (univariate normal). This is exactly the thing our $\bar{Y}_n$ converges in distribution to.
\[\sqrt{n}(\bar{Y}_n - \mathbf{v}^T\mathbf{\mu}_{\mathbf{X}}) \xrightarrow[n \to \infty]{(d)} \mathbf{v}^T\mathcal{N}_d (\mathbf{0}, \Sigma_{\mathbf{X}})\]Finally we can also write
\[\begin{aligned} \bar{Y}_n &= \frac{1}{n}\sum_{i=1}^n Y_i\\ &= \frac{1}{n}\sum_{i=1}^n \mathbf{v}^T \mathbf{X}_i\\ &=\frac{1}{n}\mathbf{v}^T \left(\sum_{i=1}^n \mathbf{X}_i\right)\\ &=\mathbf{v}^T \bar{\mathbf{X}}_n \end{aligned}\]So we have
\[\mathbf{v}^T\sqrt{n}(\bar{X}_n - \mathbf{\mu}_{\mathbf{X}}) \xrightarrow[n \to \infty]{(d)} \mathbf{v}^T\mathcal{N}_d(\mathbf{0}, \Sigma_{\mathbf{X}})\]which by Slutsky’s theorem let’s us conclude
\[\sqrt{n}(\bar{X}_n - \mathbf{\mu}_{\mathbf{X}}) \xrightarrow[n \to \infty]{(d)} \mathcal{N}_d(\mathbf{0}, \Sigma_{\mathbf{X}})\]

Comments